
OpenClaw Token 永久自由且免費! Ollama 本地部署完全指南
文章更新:本文之前提到的模型有些過舊,是由於某些參考來源中的模型相對過時所導致。通常來說,越新的模型性能越強。當然了,本文關鍵是向大家說明Ollama 的部署流程,而不是模型效能評測比較。大家可以直接把文中提到的模型,替換為最新的模型即可。對於算力有限的朋友,可以部署體積較小的版本作為入門探索。
綜合來說,目前2026 社群普遍認可的頂級開源LLM:
你有沒有算過,用雲端API 跑OpenClaw 一個月要花多少錢?
有用戶分享,一個配置不當的 [心跳檢查 heartbeat ack](每30 分鐘一次),一晚上就燒掉了18.75 美元;還有人單日待機就消耗了5000 萬Tokens,折合約11 美元。更誇張的是,有人用GPT-5 Pro 等級API 跑複雜任務,一個月帳單直接突破300 美元。
但如果我告訴你,同樣的OpenClaw,可以做到完全免費、斷網可用、資料永不出本機-你信嗎?
答案就是三個字:Ollama。
為什麼Ollama + OpenClaw 是2026 年最值得關注的組合?
先說一個數據:截至2026 年3 月,OpenClaw 在GitHub 上的Star 數已經突破歷史新高,社區貢獻的Skills 插件超過1700 個,覆蓋文件管理、PDF 編輯、語音識別、郵件處理、智能家居控制等幾乎所有你能想到的場景。
而Ollama,作為目前最受歡迎的本地大模型運行工具,支援一鍵部署Qwen、Llama、GLM、DeepSeek 等主流開源模型,不需要複雜的CUDA 配置,不需要深入了解底層技術,甚至不需要連網。
這兩個項目的結合,意味著什麼?
意味著你可以在自己的電腦上,零成本運行一個功能完整的AI Agent——它能幫你管理文件、自動回覆訊息、監控伺服器、甚至在你睡覺時清理GitHub 的過期Issue。
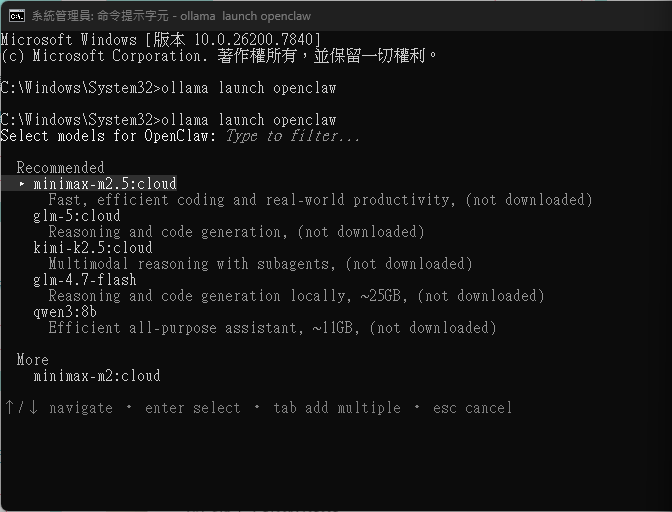
從Ollama 0.17 版本開始,只需要一條指令,你就可以在本地部署OpenClaw:
ollama launch openclaw如果你的系統上還沒有安裝OpenClaw,Ollama 會自動偵測並彈出安裝提示,選擇Yes 即可。整個過程不超過10 分鐘。
雲端API 的真實成本
| 模型 | 輸入價格(每百萬Token) | 輸出價格(每百萬Token) |
|---|---|---|
| GPT-5.2 Pro | 21 美元 | 168 美元 |
| Claude Opus 4.5 | 15 美元 | 75 美元 |
| Llama 3.3 70B(OpenRouter) | 0.12 美元 | 0.30 美元 |
對於輕度用戶(每天1 萬- 10 萬Token),雲端API 確實更划算,月費接近零。
但如果你是重度用戶(每天3,000 萬+ Token),雲端成本將飆升至每月9,000 美元以上。而同樣的工作量,本地部署的話,在扣除一次性配置成本以後,你就能自己源源不斷地生產屬於自己的token。
硬體需求:你的電腦能跑嗎?
這可能是大家最關心的問題。好消息是:門檻比你想像的低很多。
GPU 顯存與模型對應關係
| 顯存 | 可運行模型 | 推薦方案 |
|---|---|---|
| 4 GB | Qwen2.5:4B 等輕量模型 | 能用,但速度較慢 |
| 8 GB | 大部分7B 模型 | 入門首選,體驗流暢 |
| 16-24 GB | 14B – 32B 模型 | 最佳性價比區間 |
| 48 GB+ | 70B+ 大模型 | 接近雲端體驗 |
最低配置要求
- CPU:Intel i5 / AMD Ryzen 5 以上
- 記憶體:8 GB(最低),16 GB(建議),32 GB(最佳)
- 儲存:至少20 GB 剩餘空間,強烈建議SSD
- GPU:NVIDIA 顯示卡優先(RTX 3060/4060/5060 系列皆可)
Apple Silicon 用戶的福音:如果你用的是M1/M2/M3/M4 系列Mac,統一記憶體架構天然適合跑本地模型。一台16 GB 記憶體的MacBook Air 就能流暢運行7B 模型,32 GB 的MacBook Pro 甚至可以駕馭14B 機型。
沒有獨立GPU 也不用擔心-Ollama 支援純CPU 推理,只是速度會慢一些。對於Qwen3.5:cloud 或Qwen3:0.6b 這類超輕量模型,即使沒有GPU,也能在幾秒內給予回應。